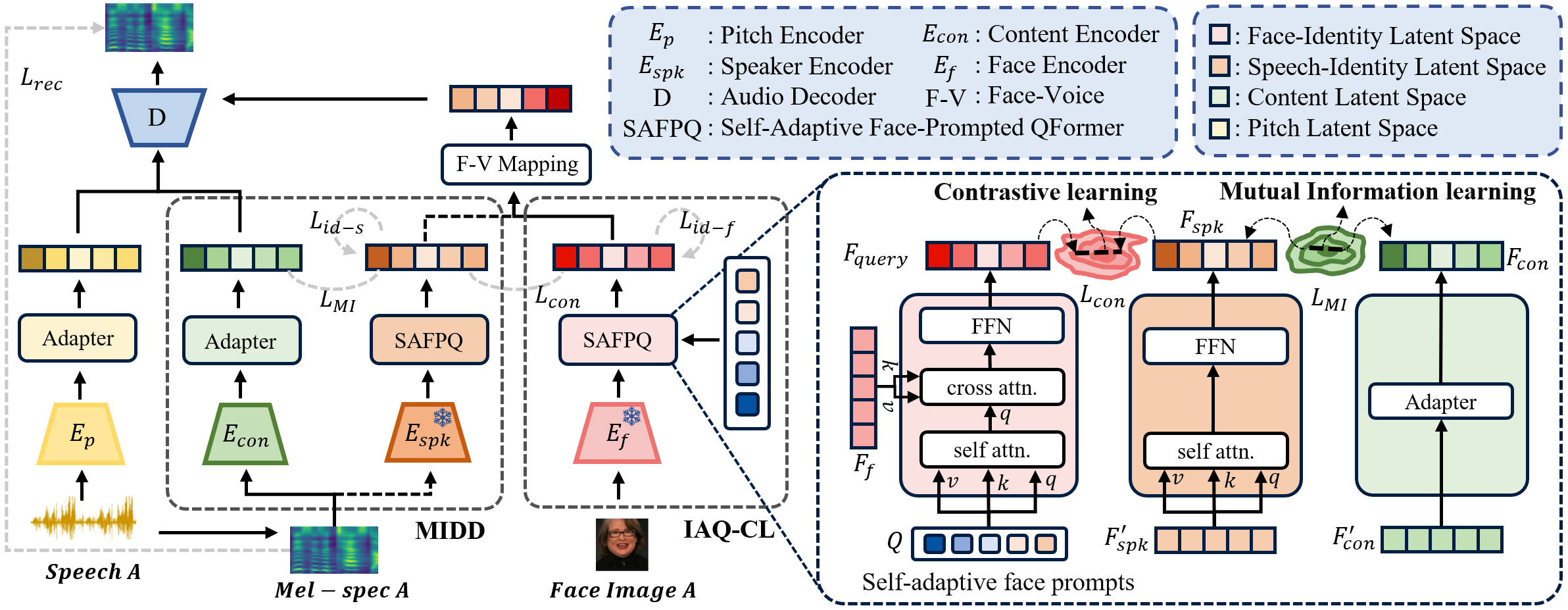
Abstract
Face-based Voice Conversion (FVC) is a novel task that leverages facial images to generate the target speaker's voice style. Previous work has two shortcomings: (1) suffering from obtaining facial embeddings that are well-aligned with the speaker's voice identity information, and (2) inadequacy in decoupling content and speaker identity information from the audio input. To address these issues, we present a novel FVC method, Identity-Disentanglement Face-based Voice Conversion (ID-FaceVC), which overcomes the above two limitations. More precisely, we propose an Identity-Aware Query-based Contrastive Learning (IAQ-CL) module to extract speaker-specific facial features, and a Mutual Information-based Dual Decoupling (MIDD) module to purify content features from audio, ensuring clear and high-quality voice conversion. Besides, unlike prior works, our method can accept either audio or text inputs, offering controllable speech generation with adjustable emotional tone and speed. Extensive experiments demonstrate that ID-FaceVC achieves state-of-the-art performance across various metrics, with qualitative and user study results confirming its effectiveness in naturalness, similarity, and diversity.
Released Code: we will release the code upon publication of our paper.
1. ID-FaceVC Examples
1. Generation results by different methods.
Sample 1
| Source Speaker | Target Speaker |
 |
 |
| Source utterance | Reference utterance |
| FaceVC | SP-FaceVC | FVMVC | FaceTTS | ID-FaceVC | |
| Converted utterance |
Sample 2
| Source Speaker | Target Speaker |
 |
 |
| Source utterance | Reference utterance |
| FaceVC | SP-FaceVC | FVMVC | FaceTTS | ID-FaceVC | |
| Converted utterance |
Sample 3
| Source Speaker | Target Speaker |
 |
 |
| Source utterance | Reference utterance |
| FaceVC | SP-FaceVC | FVMVC | FaceTTS | ID-FaceVC | |
| Converted utterance |
Sample 4
| Source Speaker | Target Speaker |
|
 |
| Source utterance | Reference utterance |
| FaceVC | SP-FaceVC | FVMVC | FaceTTS | ID-FaceVC | |
| Converted utterance |
Sample 5
| Source Speaker | Target Speaker |
 |
|
| Source utterance | Reference utterance |
| FaceVC | SP-FaceVC | FVMVC | FaceTTS | ID-FaceVC | |
| Converted utterance |
2. Ceneration results by different target speaker.
Sample 1
| Target Speaker Image1 | Target Speaker Image2 | Target Speaker Image3 | |
 |
|
 |
|
| Reference Utterance | |||
| FaceVC | |||
| SP-FaceVC | |||
| FVMVC | |||
| FaceTTS | |||
| ID-FaceVC |
Sample 2
| Target Speaker Image1 | Target Speaker Image2 | Target Speaker Image3 | |
 |
 |
 |
|
| Reference Utterance | |||
| FaceVC | |||
| SP-FaceVC | |||
| FVMVC | |||
| FaceTTS | |||
| ID-FaceVC |
Sample 3
| Target Speaker Image1 | Target Speaker Image2 | Target Speaker Image3 | |
 |
 |
 |
|
| Reference Utterance | |||
| FaceVC | |||
| SP-FaceVC | |||
| FVMVC | |||
| FaceTTS | |||
| ID-FaceVC |
2. Style Control for Text Input
Text Input: Why do I believe this? I don’t know the details of what happened.
| Target Speaker Image 1 | Target Speaker Image 2 | ||
 |
 |
||
| calm | calm | ||
| whispering | whispering | ||
| angry | terrified | ||
| sad | sad | ||
| speed=0.8 | speed=0.8 | ||
| speed=1.2 | speed=1.2 |
3. Diversity of Generated Voice
Speech generated by different face inputs.
| Female face 1 | Female face 2 | Female face 3 | Female face 4 | Female face 5 | Female face 6 |
|
|
|
|
|
 |
| Male face 1 | Male face 2 | Male face 3 | Male face 4 | Male face 5 | Male face 6 |
|
|
 |
 |
 |
|
4. Rebuttal Supplement
Performance on two challenge out-of-domain scenarios (VGGFace2 and Voxceleb2 datasets).
Sample 1
| Target Speaker Image 1 | Target Speaker Image 2 | Target Speaker Image 3 | Target Speaker Image 4 |
 |
 |
 |
 |
| Target Speaker Image 5 | Target Speaker Image 6 | Target Speaker Image 7 | Target Speaker Image 8 |
 |
 |
 |
 |
Sample 2
| Target Speaker Image 1 | Target Speaker Image 2 | Target Speaker Image 3 | Target Speaker Image 4 |
 |
 |
 |
 |
| Target Speaker Image 5 | Target Speaker Image 6 | Target Speaker Image 7 | Target Speaker Image 8 |
 |
 |
 |
 |